MoMA: Multimodal LLM Adapter for Fast Personalized
Image Generation

[Paper] [Code] [HuggingFace] [Online Demo]
Accepted by ECCV 2024
[Paper] [Code] [HuggingFace] [Online Demo]
Accepted by ECCV 2024
In this paper, we present MoMA: an open-vocabulary, training-free personalized image model that boasts flexible zero-shot capabilities. As foundational text-to-image models rapidly evolve, the demand for robust image-to-image translation grows. Addressing this need, MoMA specializes in subject-driven personalized image generation. Utilizing an open-source, Multimodal Large Language Model (MLLM), we train MoMA to serve a dual role as both a feature extractor and a generator. This approach effectively synergizes reference image and text prompt information to produce valuable image features, facilitating an image diffusion model. To better leverage the generated features, we further introduce a novel self-attention shortcut method that efficiently transfers image features to an image diffusion model, improving the resemblance of the target object in generated images. Remarkably, as a tuning-free plug-and-play module, our model requires only a single reference image and outperforms existing methods in generating images with high detail fidelity, enhanced identity-preservation and prompt faithfulness. We commit to making our work open-source, thereby providing universal access to these advancements.
We present MoMA, a multimodal LLM adapter enhanced by fine-grained feature transfer. The overall architecture is demonstrated in the Figure below. Our method consists of three parts: (1) a generative multimodal decoder is utilized to extract image features from the reference image and edit it following the target prompt, yielding the contextualized image feature; (2) we replace the background of the original image by white color, leaving only object pixels, and leverage the original UNet’s self-attention layers to extract the object image feature; (3) finally, during the new image generation process, we injected the contextualized image features and the object image features into the UNet diffusion model with the dedicatedly trained context-cross-attention layers and object-cross-attention layers, respectively.
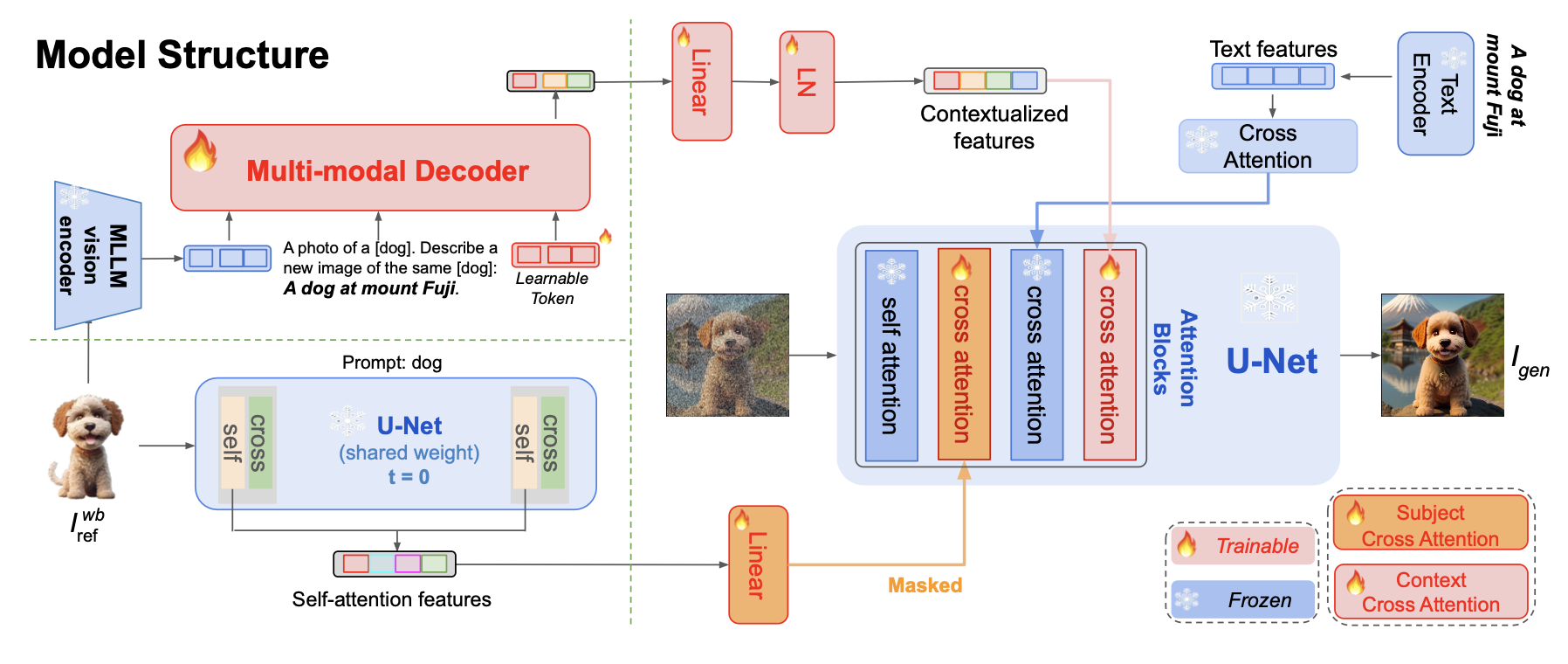
To achieve the best model performance, we propose a two-staged pre-training strategy. First, we propose a Multimodal Generative Learning Stage, where we pre-train the multimodal image-feature decoder such that it learns to compose image features of the subject with the target prompt and output the CLIP embedding of the target image. Second, subject and context cross attention layers are trained to inject this embedding. To further enhance the detail faithfulness, we involve image self-attention features transfer and apply a masking mechanism

We present qualitative examples to illustrate the effectiveness of our model. In the Figure below, the target prompts specify a novel contextual environment. Our model seamlessly generates a high-quality background while precisely situating the same object within this new setting

In the following image, the prompts indicate a change in texture. Our model showcases its ability to render realistic textures in response to the textual cues, adeptly altering specified visual elements while leaving other identity aspects of the image unaffected..

Zero-shot Qualitative Comparison. We share recontextualization in the upper panel and texture editing in the lower panel. Our results have significantly more accurate details for context editing and better balancing between prompt and image fidelity in texture editing.

Our model is a universal adapter because we freeze the original diffusion model in the training stage. It can generalize to the custom model checkpoints fine-tuned from the same base model. In Figure below, we verify this on community models from HuggingFace and CivitAi including Realistic Vision V4.0, ReV-Animated, Anything v4, and Esthetic Retro Anime. These models are all fine-tuned from SD v1.5. MoMA can be directly applied to these community models without any modification..

@article{song2024moma,
title={MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation},
author={Song, Kunpeng and Zhu, Yizhe and Liu, Bingchen and Yan, Qing and Elgammal, Ahmed and Yang, Xiao},
booktitle={arXiv preprint arXiv:2404.05674},
year={2024}
}